MySql 语句执行顺序
一、手写SQL顺序
select <select_list> from <table_name> <join_type> join <join_table> on <join_condition> where <where_condition> group by <group_by_list> having <having_condition> order by <order_by_condition> limit <limt_number>
二、MySql执行顺序
from <left table> on <on_condition> <join_type> join <join_table> where <where_condition> group by <group_by_list> <sum()avg()等聚合函数> having <having_condition> select <select_list> distinct order by <order_by_condition> limit <limit_number>
三、MySql执行顺序理解
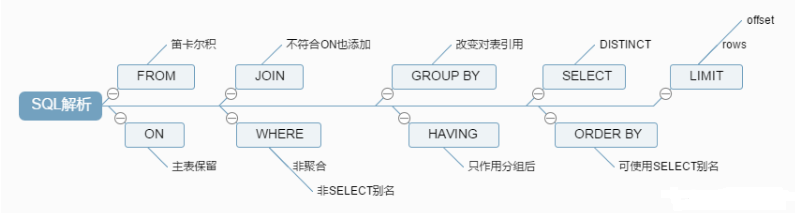
第一步:加载from子句的前两个表计算笛卡尔积,生成虚拟表vt1;
第二步:筛选关联表符合on表达式的数据,保留主表,生成虚拟表vt2;
第三步:如果使用的是外连接,执行on的时候,会将主表中不符合on条件的数据也加载进来,做为外部行;
第四步:如果from子句中的表数量大于2,则重复第一步到第三步,直至所有的表都加载完毕,更新vt3;
第五步:执行where表达式,筛选掉不符合条件的数据生成vt4;
第六步:执行group by子句。group by 子句执行过后,会对子句组合成唯一值并且对每个唯一值只包含一行,生成vt5,。一旦执行group by,后面的所有步骤只能得到vt5中的列(group by的子句包含的列)和聚合函数;
第七步:执行聚合函数,生成vt6;
第八步:执行having表达式,筛选vt6中的数据。having是唯一一个在分组后的条件筛选,生成vt7;
第九步:从vt7中筛选列,生成vt8;
第十步:执行distinct,对vt8去重,生成vt9。其实执行过group by后就没必要再去执行distinct,因为分组后,每组只会有一条数据,并且每条数据都不相同;
第十一步:对vt9进行排序,此处返回的不是一个虚拟表,而是一个游标,记录了数据的排序顺序,此处可以使用别名;
第十二步:执行limit语句,将结果返回给客户端;
四、其他
1、on和where的区别?
简单地说,当有外关联表时,on主要是针对外关联表进行筛选,主表保留,当没有关联表时,二者作用相同。
例如在左外连时,首先执行on,筛选掉外连表中不符合on表达式的数据,而where的筛选是对主表的筛选。
2、图解
原文章来源于:https://www.cnblogs.com/zhangbl55666/p/14279752.html
本站文章主要用于个人学习记录,可能对您有所帮助,仅供参考!

