MySQL中count统计哪种更快
一. MySQL 的逻辑架构图
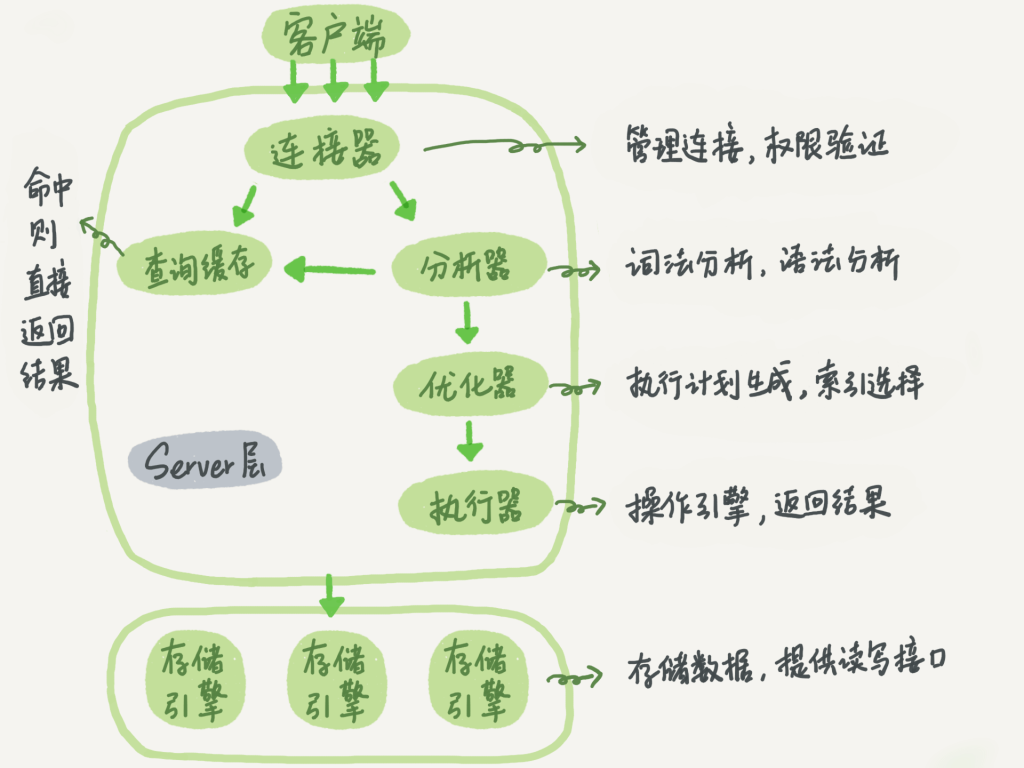
二. 对比各种count方法(以Innodb为例)
1.count(*)
InnoDB存储引擎遍历整张表,但不取值。server 层对于返回的每一行,不判断是否为空,直接按行累加。2.count(1)
InnoDB存储引擎遍历整张表,但不取值。server 层对于返回的每一行,放一个数字"1"进去,判断是否为空(值不会为空,但逻辑如此),不为空则按行累加。3.count(主键)
a). InnoDB存储引擎会遍历整张表,把每一行的【主键值】取出来,返回给 server 层。server 层拿到【主键值】后,判断是否为空(主键不会为空,但逻辑如此),不为空则按行累加。
b). 返回【主键值】,会涉及解析行数据以及拷贝字段值的操作4.count(字段)
a). 字段不可空(Not Null):InnoDB存储引擎会遍历整张表,把每一行的【字段值】取出来,返回给 server 层。server 层拿到【字段值】后,按行累加。
b). 字段可空(Null):InnoDB存储引擎会遍历整张表,把每一行的【字段值】取出来,返回给 server 层。server 层拿到【字段值】后,判断是否为空,不为空则按行累加。
c). 返回字段值,会涉及解析行数据以及拷贝字段值的操作三. 结论
- 【不取值】可以理解为:返回了一行,但是只有0个字段
- count统计不一定会走主键索引,而是根据查询条件选择最小的索引树
- 按照效率排序,count(字段) < count(主键 id) < count(1) ≈ count(),所以尽量使用 count()
本站文章主要用于个人学习记录,可能对您有所帮助,仅供参考!

